結論ファースト
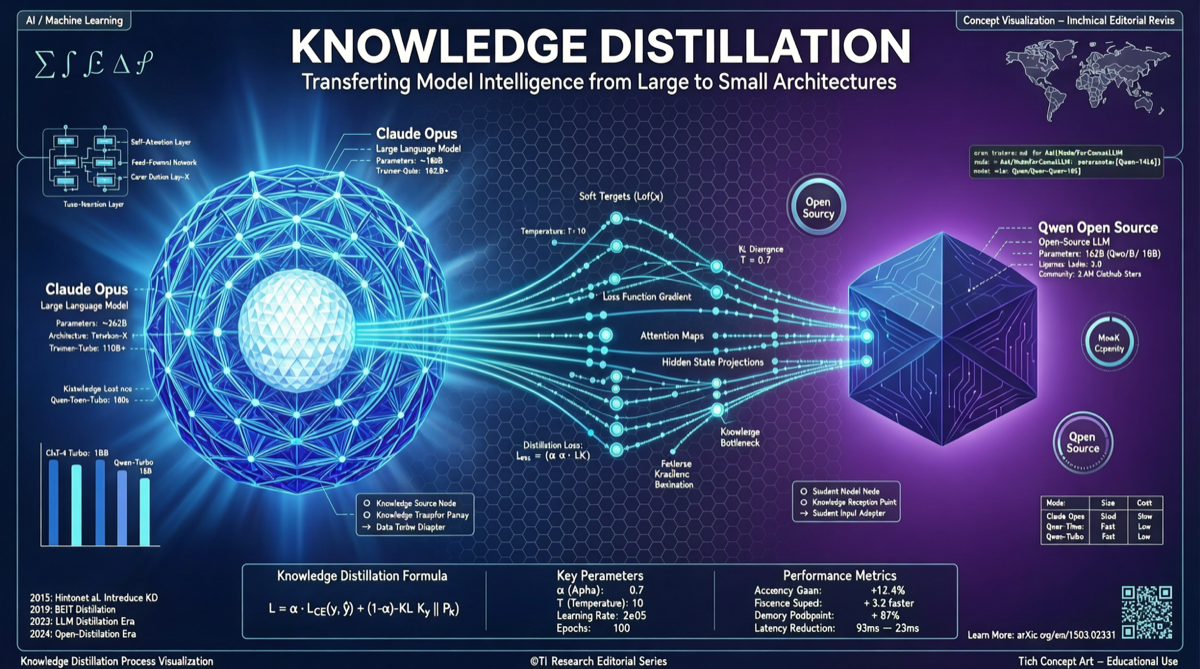
HuggingFaceコミュニティ開発者Jackrong氏がQwen3.6 35B A3B蒸留版をリリースした。Claude Opusの推論出力を用いた知識蒸留によって訓練されたモデルで、ファイルサイズは71.9GB。GGUF量子化版も近日公開予定。
これが意味すること:コミュニティはクローズドソースのフラッグシップモデルの推論データをオープンモデルに「注入」し、オープンモデルをクローズドソースのフラッグシップに迫る推論能力に引き上げている。この「蒸留→蒸留→蒸留」のパターンは、オープンソースコミュニティがクローズドソースモデルに追いつくための核心的なパスになりつつある。
技術アーキテクチャの分解
基本アーキテクチャ
| 項目 | 内容 |
|---|---|
| ベースモデル | Qwen3.6 35B A3B(MoEアーキテクチャ) |
| 蒸留ソース | Claude Opus 推論出力 |
| モデルサイズ | 71.9GB(FP16) |
| 公開者 | Jackrong(HFコミュニティで著名な蒸留モデル作者) |
| プラットフォーム | HuggingFace |
| 量子化版 | GGUF近日公開予定 |
なぜQwen3.6 35B A3Bなのか?
Qwen3.6 35B A3Bは**MoE(Mixture of Experts)**アーキテクチャのモデルで、以下の特徴を持つ:
- 総パラメータ数:35B
- アクティブパラメータ数:約3B(A3B = Active 3 Billion)
- 推論効率が高い:実行時に3Bパラメータのみをアクティブ化、小型モデル並みの速度
- 知識容量が大きい:35Bの総パラメータ数が膨大な知識を蓄積
Claude Opusの推論データをこのアーキテクチャに蒸留することは、「高速なシャーシ」に「フラッグシップ級のエンジン」を搭載するようなものだ。
蒸留の方法論
Claude Opus 推論データ(教師)
↓
高品質な推論チェーンを生成
↓
Qwen3.6 35B A3B(生徒)
↓
推論パターンの学習+知識転移
↓
蒸留後のオープンソースモデル
この蒸留アプローチの核心的な優位性:
- Claudeの重み漏洩なし:出力のみを蒸留、モデル内部パラメータには触れない
- 推論能力の転移が可能:Claude Opusの連鎖推論、計画、内省の能力を蒸留によって受け渡せる
- コスト効率が高い:一度の推論データで永続的に利用可能なオープンモデルを獲得
比較分析
| 項目 | 原版 Qwen3.6 35B | 蒸留版(Opusデータ) | Claude Opus 4.6 |
|---|---|---|---|
| パラメータ規模 | 35B(アクティブ3B) | 35B(アクティブ3B) | 非公開、数百Bと推定 |
| 推論能力 | Qwenネイティブ | Opus推論パターン融合 | フラッグシップ級 |
| 推論速度 | 高速(3Bアクティブ) | 高速(3Bアクティブ) | APIに依存 |
| オープンソース | ✅ | ✅ | ❌ |
| ローカルデプロイ | ✅ | ✅ | ❌ |
| コスト | 無料 | 無料 | トークン課金 |
クイックスタートガイド
ハードウェア要件
| 構成 | 推奨セットアップ |
|---|---|
| 最小 | 24GB VRAM(GGUF Q4量子化が必要) |
| 推奨 | 48GB VRAM(GGUF Q8またはFP16一部レイヤー) |
| 理想的 | 80GB VRAM(A100/H100、FP16全精度) |
| Mac | 96GB以上ユニファイドメモリ(M2/M3 Max) |
期待される用途
- ローカル推論の強化:コンシューマーハードウェアでOpusレベルの推論を実現
- エージェント基盤モデル:自律型エージェントのコア推論エンジン
- 二次蒸留のベース:さらに小型モデル(7B、14B)への蒸留が可能
- ファインチューニングのベース:蒸留の上に特定ドメイン向けのSFTを実施
市場格局の判断
この蒸留モデルは明確なトレンドを表している:オープンソースコミュニティは「クローズドソースのフラッグシップ出力を蒸留する」ことで能力差を急速に縮めている。
Jackrong氏は過去にも複数の成功した蒸留プロジェクトを提供してきた。Qwen3.6 35B A3Bをベースとして選択したことは、このMoEアーキテクチャがコミュニティ内で急速に認知度を高めていることを示している。ローカルで強力な推論能力が必要なシナリオにとって、これは注目すべき選択肢だ。